
월루를 꿈꾸는 대학생
PKOS 4주차 모니터링 본문

‘24단계 실습으로 정복하는 쿠버네티스’ 책을 기준하여 정리하였습니다.
http://www.yes24.com/Product/Goods/115187666
24단계 실습으로 정복하는 쿠버네티스 - YES24
실무 현장의 경험을 고스란히 담은 쿠버네티스 실습서!직접 해야만 알 수 있는 것들이 있다. 쿠버네티스도 마찬가지다. 쿠버네티스의 기반이 되는 컨테이너 기술은 기존의 가상 머신과 기본 전
www.yes24.com
metric-server
- node의 cAdvisor 를 통해 파드의 정보를 수집한 후 제공


프로메테우스 설치
# 배포
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 45.7.1 \
--set prometheus.prometheusSpec.scrapeInterval='15s' --set prometheus.prometheusSpec.evaluationInterval='15s' \
-f monitor-values.yaml --namespace monitoring
웹에서 확인
프로메테우스는 pull 방식
- 땡겨온다 ... exporter에서 메트릭을 땡겨옴

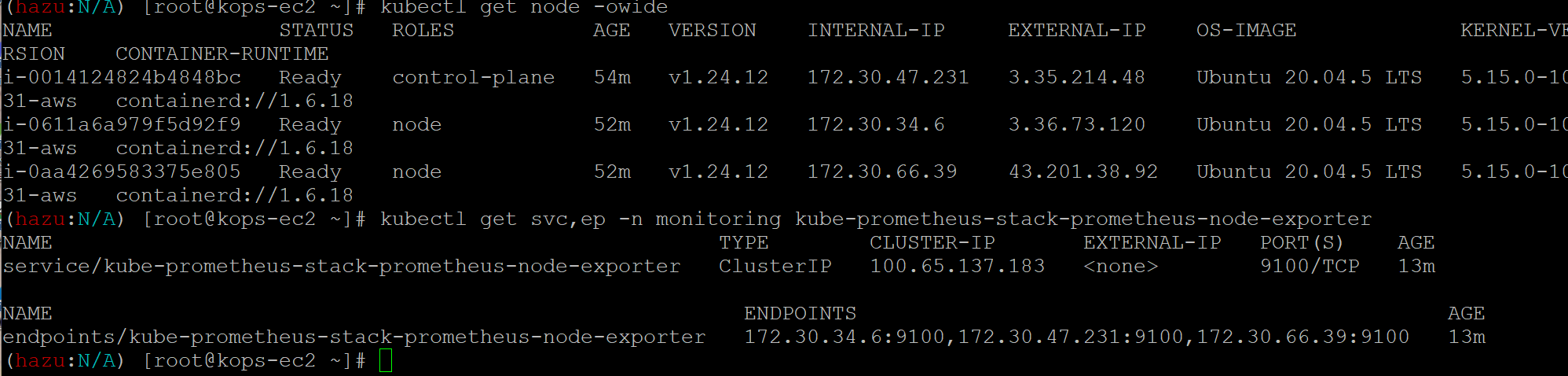
서비스로 보면 node-exporter가 있음
3개의 ip에 9100포트를 열어둠
해당 ip는 노드의 ip
노드의 정보를 tcp 9100으로 가져갈 수 있도록 제공해줌 파드가 노드안에 동작하면서 9100으로 노드의 정보들을 제공하고 이걸 프로메테우스가 pull방식으로 땡겨와서 수집
각종 설정들을 확인할 수 있음

pull로 땡겨온 타겟들 정보 확인

그라파나
- 데이터를 시각화
- 데이터 자체를 저장하지 않기 때문에 프로메테우스랑 연계해서 사용

스택으로 설치해서 기본 프로메테우스 정보가 세팅되어 있고
exporter로 보게 되면 노드별로도 모니터링 시각화가 가능

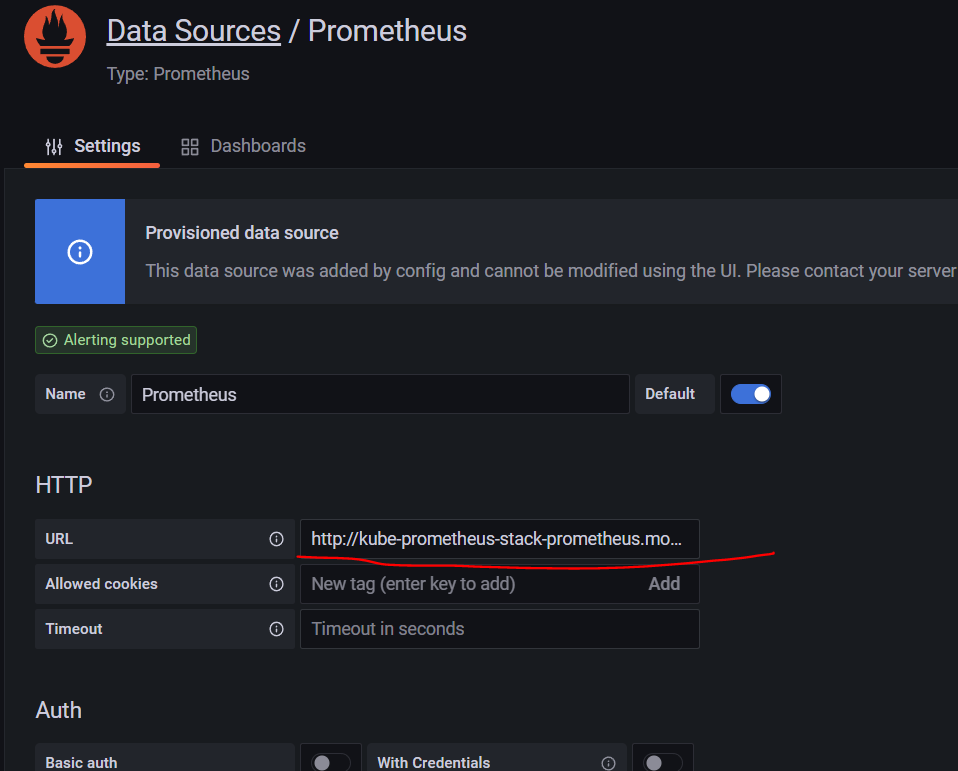
해당 소스의 주소는 ip확인 결과 서비스의 주소

대시보드 테마 변경
https://grafana.com/grafana/dashboards/13770-1-kubernetes-all-in-one-cluster-monitoring-kr/
1 Kubernetes All-in-one Cluster Monitoring KR | Grafana Labs
Edit Delete Confirm Cancel
grafana.com
필요한 대시보드의 id를 확인 ex 13770
그라파나 -> 대쉬보드 > import dashboard 선택

적용하면 바뀌게 됨

cat <<EOT > ~/nginx-values.yaml
// 메트릭 제공 true
// 제공에 사용될 포트는 9113
// 서비스모니터링 true , 네임스페이스 설정, 인터벌설정
metrics:
enabled: true
service:
port: 9113
serviceMonitor:
enabled: true
namespace: monitoring
interval: 10s
EOT
파드에 9113접근 후 정보 가지고와서 수집됨

프로메테우스 타겟쪽에 확인ㄷ ㅚㅁ

그라파나에 12708 id를 통해 대쉬보드를 가시화

프로메테우스 얼럿매니저
- 프로메테우스 메트릭 중 임계값 넘어가면 경고 메세지를 전달 그리고 이를 메일이나 슬랙에 전달 할 수 있음
- alerts ,silences , status 로 이뤄짐

얼럿매니저는 ui가 친숙하지 않아서 karma 컨테이너로 확인해도 됨
docker run -d -p 80:8080 -e ALERTMANAGER_URI=https://alertmanager.$KOPS_CLUSTER_NAME ghcr.io/prymitive/karma:latest
docker run -d -p 80:8080 -e ALERTMANAGER_URI=https://alertmanager.$KOPS_CLUSTER_NAME ghcr.io/prymitive/karma:latest
프로메테우스에 Alerts발생하면 얼럿매니저로 넘어감
프로메테우스에 설정된 룰 중 Firing이 되면 임계값을 초과한 거니까 경고가 발생되고 이 경고각 얼럿매니저에 전달되고 전파가 됨
레이블이 잘못 설정되어 있어서 경고라고 뜨는 것도 있음
# 추가
kubectl label $(kubectl get pod -n kube-system -l k8s-app=kube-controller-manager -oname) -n kube-system component=kube-controller-manager
# 확인
kubectl get svc,ep -n kube-system kube-prometheus-stack-kube-controller-manager
# 추가
kubectl label $(kubectl get pod -n kube-system -l k8s-app=kube-scheduler -oname) -n kube-system component=kube-scheduler
# 확인
kubectl get svc,ep -n kube-system kube-prometheus-stack-kube-scheduler레이블을 다시 설정해주면 경고가 사라짐

PLG
- Promtal + Loki + Grafana
- Promtail : 로그 데이터를 Loki에 전달
- Loki : 시계열 데이터를 저장하는 디비
- Grafana : 데이터 시각화
로키 배포


Promtail 설치
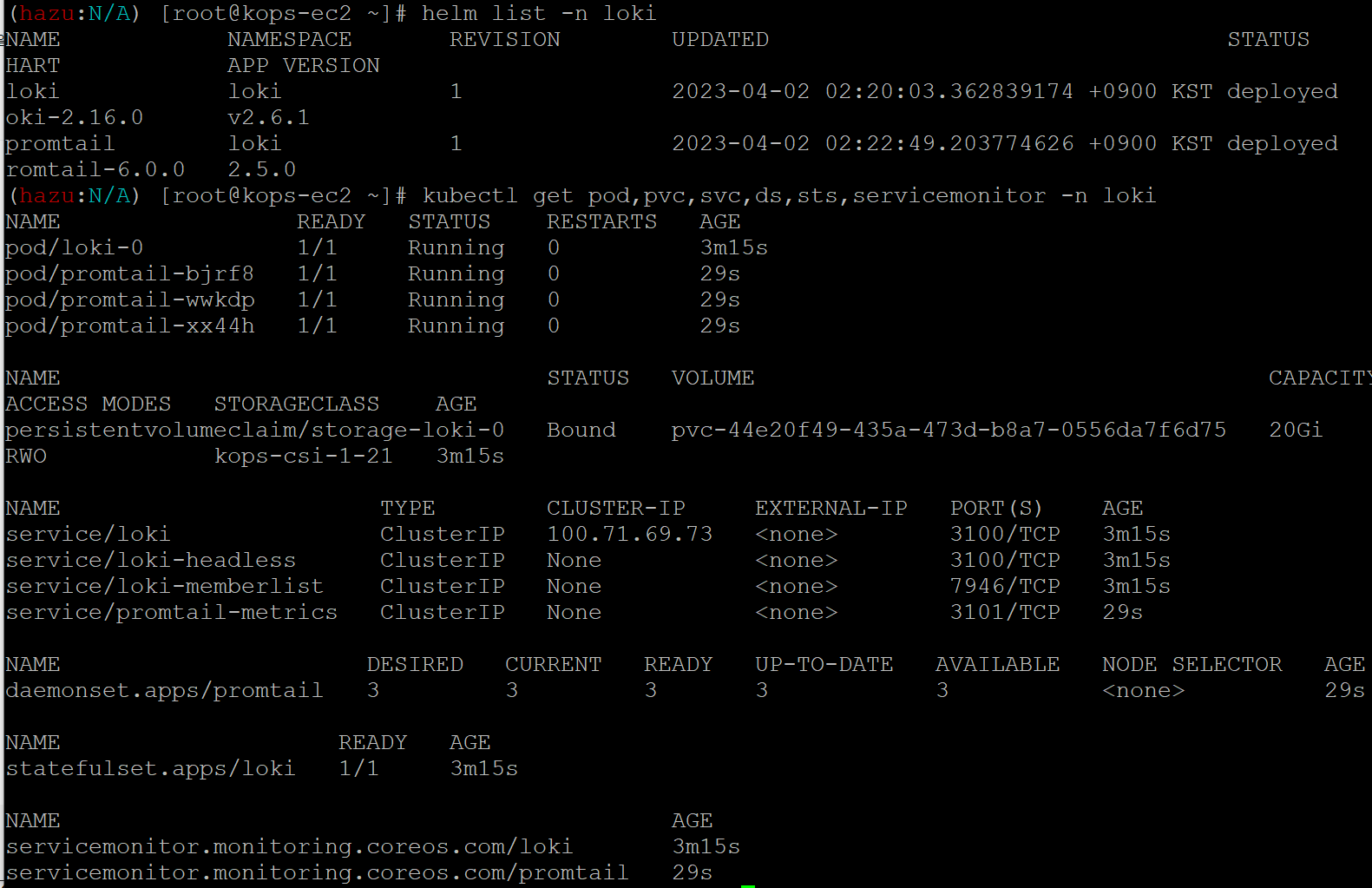
그라파나에서 로키추가
데이터소스 -> 추가 -> 로키


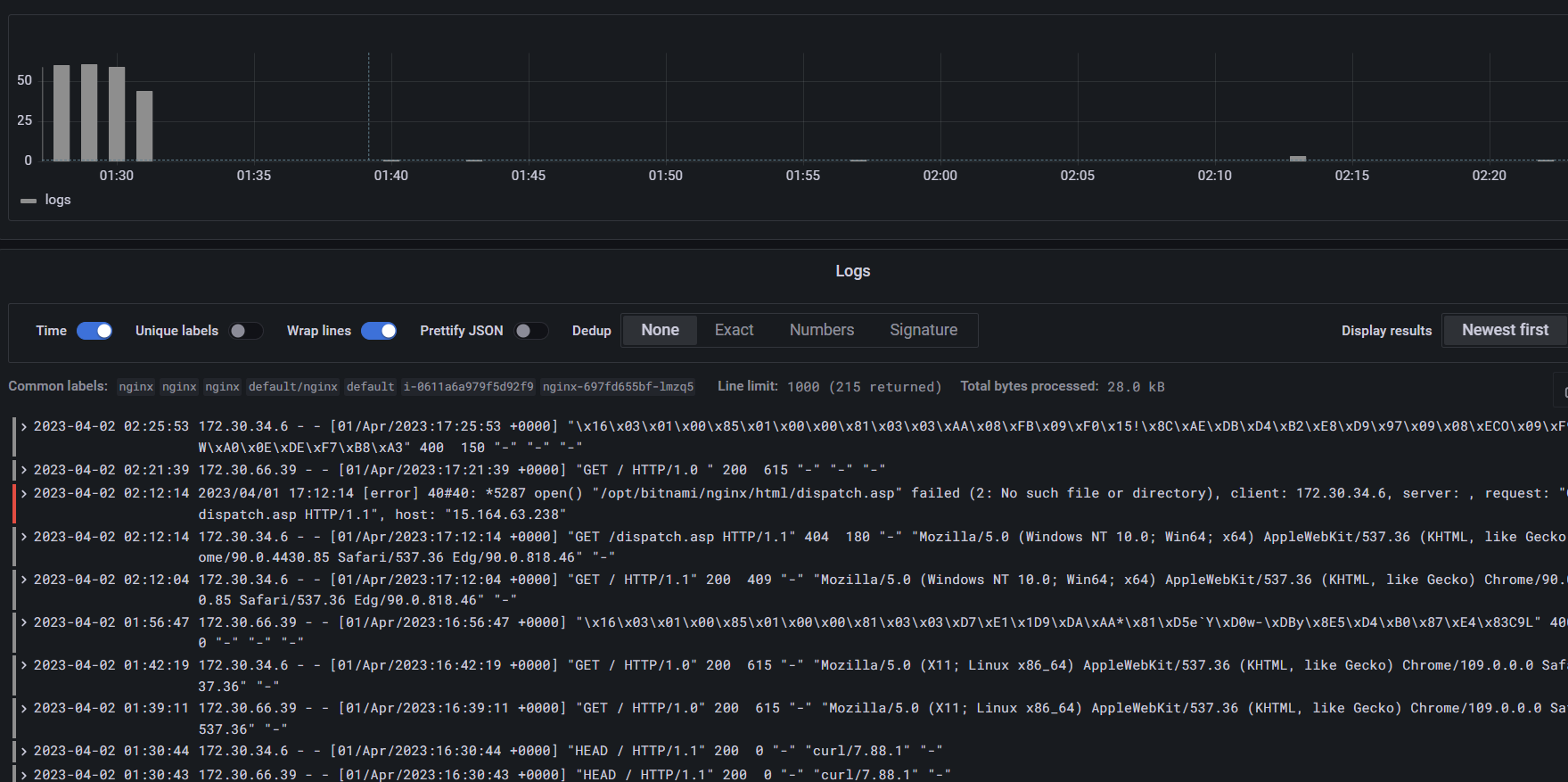
익스플로러에서 로키로 선택하고 볼 로그 종류 확인

'Server&Network > Kubernets_Dokcer' 카테고리의 다른 글
| PKOS 5주차 보안 (0) | 2023.04.09 |
|---|---|
| PKOS 3주차 GitOps (0) | 2023.03.26 |
| PKOS 2주차 (1) | 2023.03.19 |
| PKOS 1주차 (2) | 2023.03.12 |
| 로컬에서 k8s 구축하기 (1) | 2023.03.04 |



